위 문제의 경우 1개의 우선순위큐를 통해 구할 수 있다. 이런 그리디 문제가 나는 비슷한 문제가 많으니 기억해두자.
일단 입력 받은 가방과 보석을 모두 오름차순으로 정렬 한다.
그 후 작은 가방 하나씩 꺼내고, 보석 배열을 순회하면서 집어넣을 수 있는 보석을 우선순위 큐에 집어 넣는다. (by while) 다 집어 넣었으면 우선순위 큐의 top 에 위치하는 보석을 해당 가방에 넣는 것으로 확정하고 그 다음 가방을 똑같은 방법으로 확인하는 로직이다. 말이 쉽지 직접 구현하는 건 좀 어렵다.
#define _CRT_SECURE_NO_WARNINGS#include<cstdio>#include<algorithm>#include<vector>#include<queue>#include<iostream>usingnamespace std;
typedeflonglong LL;
typedef pair<LL, LL> pii;
int n, k;
intmain(){
ios_base::sync_with_stdio(0);
cin.tie(0); //cin 실행속도 향상scanf("%d %d", &n, &k);
vector<pii> jewl;
vector<LL> bag;
priority_queue<LL> pq;
LL m, v, t;
for (int i = 0; i < n; i++)
{
cin >> m >> v;
jewl.push_back({m, v});
}
for (int i = 0; i < k; i++)
{
cin >> t;
bag.push_back(t);
}
sort(bag.begin(), bag.end());
sort(jewl.begin(), jewl.end());
longlong answer = 0;
int idx = 0;
for (int i = 0; i < k; i++)
{
while (idx < n && jewl[idx].first <= bag[i])
{
// 가방에 넣을 수 있는지, 없는지 확인
pq.push(jewl[idx++].second);
}
if (!pq.empty())
{
// 우선순위 큐의 top에 있는 놈이 정답
answer += pq.top();
pq.pop();
}
}
cout << answer;
return0;
}
일단 용어에 대해 잡고 넘어가자. Interest points 는 keypoints 를 뜻하고 이것들은 보통 feature 라고도 불리우기도 한다.
원래 이렇게 부르는게 아니지만 비전 공학 특성 상 뭐가 정확히 정의되어있다기 보다는 자기 편하게 부르기 나름이기 때문에 그냥 이렇게 알고 넘어가자.
Correspondence
Correspondence 란 매치되는 이미지를 이야기한다. 보통 두 이미지를 비교할 때, 이거를 kernel information 으로 사용한다.
보통 matching points, patches, edges, regions across images 를 뜻한다.
Fundamental matrix
어떻게 매칭할 지에 사용한다. 다른 각도로 checking하면서 비교할 수 있기 위해 사용하는 놈이다.
다음 그림을 보자. sns 에 올려진 사진을 모아 fundamental matrix 로 correspondence 를 계산하고 어디서 찍었는지 확인할 수도 있다.
Feature points 사용
Image alignment 에 사용되기도 하고, 3D reconstruction, Motion tracking, Robot navigation, Indexing and database retrieval 에도 사용된다. 음.. 이미지에 특징점을 잡고 해당 데이터를 연산에 사용하는 모든 분야를 생각하면 될 거같다.
Panorama
갤럭시를 사용하면 Panorama 카메라가 있을 수 있다. 해당 기능을 구현하기 위해서는 여러장의 이미지를 찍은다음에 해당 이미지들의 특징점들을 잡고, correspondence 를 계산하여 이어 붙이는 로직을 구현해주어야 한다.
정확하게는 해당 특징 점을 vector 형태로 나타낸 feature descriptor 를 뽑아내고 각 vector 의 거리를 계산하면서 correspondence 를 찾는 과정을 거친다고 보면 될 것 같다.
Characteristics of good features
좋은 feature 의 특징은 다음과 같다.
Repeatability : 같은 특징은 반복된다.
Saliency : 각 feature 들은 구별된다.
Compactness and efficiency : 전체 이미지 픽셀 개수보다는 적은 개수의 feature 이어야 한다.
Locality : 특정 위치를 대표해야 한다.
◆2. Corner Detection
Mathematics
그러면 좋은 feature 들을 어떻게 계산해서 구할까?
위의 식처럼 주변의 픽셀 값과 계산해서 해당 픽셀이 도드라지는지 확인한다. 이 식으로 계산하게 되면 다음과 같은 input, output 을 알 수 있게 된다.
해당 output 을 보고 어느 부분이 좋은 feature 인지 아닌지 알 수 있다.
위의 그림을 봐보자.
특정 이미지에서 b,c,d 에 해당하는 영역에 correspondence 를 계산한 결과이다. (b)의 경우 center 부분이 나머지 픽셀들과 도드라지게 다른 것을 확인할 수 있고, (c) 는 비슷한 픽셀 데이터들이 line 처럼 존재하는 걸 확인할 수 있으며, (d) 는 그냥 전체적으로 비슷비슷하다는 것을 확인할 수 있다.
그러면 셋 중에 어떤 것이 좋은 feature 일까? 당연히 (b) 이다. 이건 그냥 넘어가겠다.
여튼 저런 식으로 corner feature 를 뽑아낼 수 있는데
식을 다음과 같이 좀더 줄여서 사용할 수 있다.
Corner response function
고유값과 고유벡터를 통해 구한다는데 정확한 것은 추가 검색을 하도록 하자..
Harris corner detector
위의 Corner response function 를 사용해서 corner 를 구하는 detector 이다. corner 를 구하는 방식은 다음과 같다.
픽셀 데이터로 되어있는 이미지를 픽셀의 변화 값에 따른 frequency 변화 값을 따로 뺄 수 있다. 이를 주파수라고 하면 해당 주파수 만을 뽑아내서 주파수 도메인으로 확인해볼 수 있다. 이 때 사용되는 변환 방법으로 푸리에 변환(Fourier transform )이 있다.
푸리에 변환을 통해 이미지를 변환하게 되면 보통 각 frequency의 Coefficient 값으로 표현한다.
이미지를 위의 그래프와 같이 각 주파수에 따른 Coefficient 만 남겨두는 식으로 압축(?!)해서 저장해둘 수가 있다. 또한 FFT의 교환법칙을 통해 CNN 에서의 for 문 3개를 쓴 세제곱 복잡도를 줄일 수 있다는 장점도 가지고 있다.
일반적으로 영상처리 비전 쪽에서 이 푸리에 변환은 영상을 개선하는데 주로 많이 쓰인다.
노이즈가 있는 입력영상의 푸리에 변환 이미지
이와 같이 푸리에 변환은 영상을 개선하기 위해 노이즈 처리하기 힘든 입력 영상을 노이즈 처리하기에 좋은 주파수영역으로 바꾼 다음 노이즈를 제거하는 역할을 수행하게 된다.
위 이미지의 오른쪽 이미지는 푸리에 변환을 수행한 spectrum magnitude 이미지이다. 이 주파수 영역을 나타내는 스펙트럼 이미지에서 입력 영상의 노이즈 부분에 해당하는, 즉 고주파 영역이나 저주파 영역에 해당하는 부분을 아래와 같이 제거해 준다면 개선된 영상을 얻을 수 있다.
노이즈 영역을 제거한 스펙트럼 영상
이렇게 스펙트럼 영상에서 노이즈 영역에 해당하는 부분을 제거하고 푸리에 역변환(IDFT)을 수행하여 원래의 입력 영상 도메인으로 바꾸면 개선된 이미지를 얻을 수 있게 된다. 푸리에 변환에 의한 필터링 과정은 다음과 같다.
이러한 필터링 과정에서 H(u, v) 부분을 구현할 때 유의해야 할 점은 F(u, v)와 같은 크기의 영상 또는 행렬로 생성하지 않고, F(u, v)의 u, v 에 따라 H(u, v)의 스칼라 값을 계산하여 F(u, v)에 곱하는 방식을 사용하게 된다.
이러한 H(u, v) 부분에 적용하여 구현 할 수 있는 필터는 다음과 같은 필터가 있다.
ⓐ 저주파 통과 필터 (Low-pass filter)
저주파 통과 필터는 F(u, v)의 저주파 영역은 통과시키고 고주파 영역은 0으로 만들어 통과시키지 않는 필터를 말한다. 영상에서 잡음을 제거하거나 또는 약화시키고 블러링하여 에지 등의 세밀한 부분을 부드럽게 만드는 역할을 한다.
ⓑ 고주파 통과 필터 (High-pass filter)
고주파 통과 필터는 F(u, v)의 고주파 영역은 통과시키고 저주파 영역은 0으로 만들어 통과시키지 않는 필터를 말한다. 고주파 통과 필터는 영상을 날카롭게 강조하는 Sharpenning 효과를 일으킨다. 입력 영상에서는 고주파 통과 필터링을 하여 IDFT 하면 변화가 없는 영역은 0의 값을, 변화가 심한 에지 영역은 양수 또는 음수의 값을 갖게 된다.
퓨리에 변환의 목표는 어떻게 영상을 저주파 성분으로 조그맣게 두었따가 고주파 성분으로 신호를 확대시켰을 때 신호가 제대로 남아있을까? 를 해결하는 것이다.
Fourier Bases
위에서 말했듯이 이미지를 Fourier Transform 하여 Coefficient 값만 남겨둔다고 했었다. 그러면 해당 Coefficient 에 해당하는 주파수는 어떻게 저장하나? 에 대한 답이 Fourier Bases 이다.
기본적인 주파수 Bases 를 따로 두어 Coefficient 데이터에 계산해주는 식으로 이미지를 복원시킬 수 있다.
Edit frequencies
보이는 그림처럼 fourier 변환하여 뽑아낸 Fourier d
ecomposition image 를 조작하여 원래 이미지를 다룰 수 있다. 위에서 말한 Low-pass filter 와 High-pass filter 도 이 decomposition image 로 다룰 수 있다.
다만 이 정도는 알아두자. 저 decomposition image 에서 가운데 원 부분이 low frequency를 나타내는 coefficient 이고, 외각으로 갈수록 high frequency 를 나타내는 coefficient 라는 것이다.
예를 들어 low frequency를 버린다는 말은 면을 거른다는 말이고, high frequency를 버린다는 말은 edge 를 버린다는 말이다.
Amplitude & Phase
저 decomposition image 는 푸리에 변환 이후의 amplitude 를 의미한다.
우측의 Phase 는 이미지의 '패턴' 을 의미한다. 보통 모공과 같은 정확한 정보를 위해서는 '패턴'을 정보화 한 phase 를 사용하는데 많이 쓰지는 않는다.
정리해서 Amptitude 가 더 사람이 이해하기 직관적인 info 이고, Phase 는 직관적인 정보 보다는 정확한 정보로써 패턴을 정보화한 정보구나~ 라는 것을 알고 있으면 될 듯 싶다.
Edge Artifact Problem
위의 가우시안 필터와 Box filter 두 가지를 통해 이미지 blur 처리를 했을 때, box filter 는 이상한 edge들이 있는 것을 확인할 수 있다. 왜 그럴까?
FT 로 설명할 수 있다. FT 는 위에서 말했듯이 교환 법칙 및 결합 법칙이 가능해서 CNN 의 복잡도를 줄일 때 사용할 수 있다고 했다.
Box filter 를 FT 하게 되면
다음과 같이 갑자기 변하는 경계면 때문에 edge artifact 가 생기게 된다.
따라서 ((IMAGE * FT) * (BoxFilter*FT)) * IFT = BlurIMAGE 에서 edge artifact 가 계속 영향을 끼치게 된다. 때문에 Box filter 로 blur 처리했을 시 edge artifact 에 의해 이상한 edge 들이 있는 것을 확인할 수 있다.
Aliasing problem
이미지 scale 을 줄였을 때 high frequency component 를 잃는 것을 Aliasing problem 이라고 한다.
허나 이렇게 말하면 직관적으로 어떤 problem 인지 확 와 닿지가 않는다. 예를 들어 동영상을 찍을 때, 자동차의 바퀴 회전이 뒤로 가는(?!) 모습으로 찍힌 것을 볼 수 있다. 이를 Aliasing problem 이라고 한다. 즉, 영상의 frame 주파수가 실제 해당 물체의 frequency를 따라가지 못해 생기는 문제이다.
이를 해결하기 위해 어떻게 해야할까?
Nyquist-Shannon Sampling Theorem
2가지의 해결 방법이 있다.
Sampling more!: 영상을 찍는다면 사진기가 찍는 frame 주파수 성능이 실제 물체의 주파수 2배 이상이 되도록 한다.
원본을 blur 하게 만든다.: 사진기를 바꿀 수 없다면 아예 실제 물체의 주파수를 blur 처리하여 줄여버린다.
javascript는 HTML과 CSS로 만들어진 웹페이지를 동적으로 변경해주는 언어. 경고창을 띄우고, 탭 인터페이스를 만들고, Drag & Drop 기능의 웹 에플리케이션을 만들수 있다.
예전에 Javascript는 원래 많이 인기없는 언어였다. 허나 구글이 지도 서비스를 내 놓자 HTML/CSS 만으로도 플래쉬와 같은 효과를 구현할 수 있다는 것을 증명. 거기에 ajax 열풍이 가세하면서 favascript의 중세는 끝이 난다. 자바스크립트의 재조명과 스티브 잡스의 플래쉬 혐오, HTML5의 등장이 맞물리면서 플래쉬의 입지가 빠르게 줄어들고 있고, 그 빈자리를 빠르게 자바스크립트가 대체하기 시작했다.
지금은 자바스크립트가 브라우저에서만 사용되는 언어에서 벗어나서 서버에서도 사용되고 (node.js) 데스크탑 에플리케이션 (adobe air)에서도 사용된다. 플래쉬 역시 그 안에서는 자바스크립트를 사용하고 있다.
자바스크립트는 기능이 별로 없는 언어이다. 그러면서도 프로그램이의 앙꼬에 해당하는 요소들 이를테면, 변수, 반복, 조건, 함수 심지어 객체까지 모두 가지고 있는 본격적인 프로그램이 언어이다.
1. 웹 브라우저 자바스크립트
순수한 자바스크립트 기술을 이용해서 웹 브라우저를 제어하는 방법에 대해 다루는 것이 간결한 방법이다. 하지만 오늘날 순수한 자바스크립트를 이용해서 웹 브라우저를 제어하는 방법은 잘 사용하지 않는다. 더 적은 코드로 더 강력한 효과를 얻을 수 있는 수단을 제공하는 각종 라이브러리를 사용하기 떄문이다.
만약 순수 자바스크립트 만으로 웹브라우저를 제어하는 것은 다소 현실성이 떨어질 것이고, 특정 라이브러리에 대해서만 공부한다면 해당 라이브러리가 제공하는 기능에 갇히게 될 것이다. 따라서 좀더 원론적으로 파보려고 한다.
DOM 이라는 것은 현재 직접 사용하지는 않는다. jquery, yui 등의 라이브러리를 이용해 간접적으로 간결하게 사용한다. 이러면 훨씬 더 적은 코드로 프로그램을 작성할 수 있다. 즉, 브라우저에서 기본적으로 제공하는 DOM이라는 가장 기본적인 개념을 알고 있어야 더 쉽고 간편하게 웹을 제어할 수 있다.
2. Javascript 로드하기
inline 방식
script 로드
외부파일에서 로드
참고로 가끔씩 script 를 head 에 위치하였는데 오류가 발생하는 경우가 두루 있다. 왜냐 스크립트를 가져오는 타이밍이 원하는 대로 일치하지 않기 때문이다. 이를 해결하기 위해
window.onload = function() { }
이라는 함수를 도입해 모든 element 에 대한 로드가 끝났을 때, 브라우저에 의해서 호출되는 함수를 사용해 오류 없이 안전하게 사용할 수 있다.
허나 script 파일은 head 태그보다 페이지의 하단에 위치시키는 것이 더 좋은 방법이다.
3. Object 모델
생활코딩 출처
웹 브라우저의 구성요소들은 하나하나가 객체화 되어 있다. 자바스크립트로 이 객체를 제어해서 웹 브라우저를 제어할 수 있게 되는 것이다. 해당 객체들은 그림과 같이 서로 계층적인 관계로 구조화되어 있다.
BOM 과 DOM 은 이 구조를 구성하고 있는 가장 큰 틀의 분류라고 할 수 있다.
BOM 은 웹페이지의 내용을 제외한 브라우저의 각종 요소들을 객체화시킨 것이다. 전역객체 window 의 프로퍼티에 속한 객체들이 이에 속한다.
DOM 은 웹페이지의 내용을 제어한다. document 객체가 이러한 작업을 담당한다. 뒤에서 알아보겠지만 특정한 선택자를 뽑아낼 수도 있고, 속성 값을 변경할 수도 있다.
4. BOM
BOM(Browser OBject Model) 이란 웹 브라우저의 창이나 프레임을 추상화해서 프로그래밍적으로 제어할 수 있또록 제공하는 수단이자 객체를 말한다.
BOM 은 전역객체인 Window 의 프로퍼티와 메소드들을 통해서 제어할 수 있다. 따라서 BOM 에 대한 공부는 window 객체의 프로퍼티와 메소드의 사용법에 대해 공부하는 거라 봐도 된다.
그러면 window 객체의 사용법에 대해 알아보자.
① 전역객체 window
거의 모든 객체들이 소속되어있는 window 객체로써 전역객체라고도 불린다. 즉, 전역객체이면서 창이나 프레임을 의미한다고 볼 수 있다.
window 객체는 식별자 window 를 통해서 얻을 수 있다. 또한 생략 가능하다. window 객체의 메소드인 alert 를 호출하는 방법은 위와 같다. 여튼, 우리가 쓰는 거의 모든 메소드들은 window 에 속한다고 볼 수 있다.
<!DOCTYPE html><html><script>var a = 1;
alert(a);
alert(window.a);
</script><body></body></html>
이러한 예제를 통해서 알 수 있는 것은 전역변수와 함수가 사실은 window 객체의 프로퍼티와 메소드라는 것이다. 또한 모든 객체는 사실 window의 자식이라는 것도 알 수 있다. 이러한 특성을 ECMAScript에서는 Global 객체라고 부른다. ECMAScript의 Global 객체는 호스트 환경에 따라서 이름이 다르고 하는 역할이 조금씩 다르다. 웹 브라우저 자바스크립트에서 window 객체는 ECMAScript의 전역객체이면서 동시에 웹브 라우저의 창이나 프레임을 제어하는 역할을 한다.
② 사용자와 커뮤니케이션 하기
HTML은 form을 통해서 사용자와 커뮤니케이션할 수 있는 기능을 제공한다. 자바스크립트에는 사용자와 정보를 주고 받을 수 있는 간편한 수단을 제공한다.
alertalert는 경고창이라고도 부르며 사용자에게 정보를 제공하거나 디버깅등의 용도로 많이 사용한다. 현재는 디버깅용도로 console.log 를 많이 사용한다.
confirmconfirm 역시 alert와 비슷한 기능을 하지만 확인을 누르면 true를 반환하고, 취소를 누르면 false를 반환한다는 점을 기억하자. 이걸로 또 상호 작용할 수 있으니까.
promptprompt 역시 경고창이 뜨는 건데 이거는 사용자로부터 입력을 받아서 그 값을 반환하는 것이다. 이 때 입력값이 없으면 null 을 반환하니 이걸 이용해서 또 코딩할 수 있을 것이다.
③ Location 객체
location 객체는 문서의 주소와 관련된 객체로 window 객체의 프로퍼티다. 이 객체를 이용해서 윈도우의 문서 URL을 변경할 수 있고, 문서의 위치와 관련해서 다양한 정보를 얻을 수 있다. 이 때 URL을 변경할 수 있다는 점을 잘 기억하자.
console.log(location.toString(), location.href);
이것은 현재 윈도우의 문서가 위치하는 URL을 알아내는 방법이다. 둘 다 비슷한 반환 값이라 어느 것을 쓰든 상관없다.
참고로 alert같은 경우는 인자로 들어오는 값은 무조건 문자열이기 때문에 객체를 인자로 넣어도 toString()으로 출력되기 때문에 loaction 을 인자로 넣으면 url을 반환하여 출력한다.
이 세상에는 아주 많은 브라우저들이 있다. 크롬, 인터넷, 파이어폭스 등등 이 들의 동작 방법은 w3c 에서의 ECMA 스펙에 따라 브라우저를 만든다. 때문에 스펙에 맞는 부분은 비슷하지만 스펙에 없는 분야는 다르게 코딩한다. 때문에 때에 따라 브라우저의 호환성을 확인해야 한다. 이런 문제를 크로스 브라우징이라고 한다.
참고로 처음으로 상용화된 성공적인 브라우저는 넷스케이프였다. 이 때 도입된 언어가 자바스크립트이다. 이 때 마이크로소프트가 ie를 만들어 브라우저 전쟁에 뛰어든다. 이 때 자바스크립트의 메소드 명칭이 서로 달라지게 되는 등 여러 불편함이 생기게 되었고, 그에 따라 웹 표준이 생겼다. 즉, 웹 표준대로 메소드 명을 통일 화 하고, 동일한 API 를 사용하도록 하였다. 때문에 이 기능을 좀 더 효율적으로 사용하는 방법으로 전쟁 방향이 바뀌게 되었다.
console.dir(navigator);
이 명령어를 통해 navigator의 모든 객체 프로퍼티를 열람할 수 있다.
appName ex) navigator.appName
웹브라우저의 이름이다. IE는 마이크로소프트 인터넷 익스플로러, 파이어폭스 크롬등은 nescape로 표시된다.
appVersion ex) navigator.appVersion
브라우저의 버전을 의미한다.
userAgent ex) navigator.userAgent
브라우저가 서버 측으로 전송하는 USER-AGENT HTTP 헤더의 내용이다.
platform 브라우저가 동작하고 있는 운영체제에 대한 정보다.
※ 기능 테스트
Navigator 객체는 브라우저 호환성을 위해서 주로 사용하지만 모든 브라우저에 대응하는 것은 쉬운 일이 아니므로 아래와 같이 기능 테스트를 사용하는 것이 더 선호되는 방법이다. 예를 들어 object.keys라는 메소드는 객체의 key 값을 배열로 리턴하는 object의 메소드다. 이 메소드는 ECMAScirpt5에 추가되었기 때문에 오래된 자바스크립트와는 호환되지 않는다. 아래의 코드를 통해서 호환성을 맞출 수 잇다.
if (!Object.keys) {
Object.keys = (function () {
'use strict';
var hasOwnProperty = Object.prototype.hasOwnProperty,
hasDontEnumBug = !({toString: null}).propertyIsEnumerable('toString'),
dontEnums = [
'toString',
'toLocaleString',
'valueOf',
'hasOwnProperty',
'isPrototypeOf',
'propertyIsEnumerable',
'constructor'
],
dontEnumsLength = dontEnums.length;
returnfunction (obj) {
if (typeof obj !== 'object' && (typeof obj !== 'function' || obj === null)) {
thrownewTypeError('Object.keys called on non-object');
}
var result = [], prop, i;
for (prop in obj) {
if (hasOwnProperty.call(obj, prop)) {
result.push(prop);
}
}
if (hasDontEnumBug) {
for (i = 0; i < dontEnumsLength; i++) {
if (hasOwnProperty.call(obj, dontEnums[i])) {
result.push(dontEnums[i]);
}
}
}
return result;
};
}());
}
⑤ 창 제어
window.open 메소드는 새 창을 생성한다. 현대의 브라우저는 대부분 탭을 지원하기 떄문에 window.open 은 새 창을 만든다. 메소드 사용법은 다음과 같다.
→ 2번째 인자의 종류
_self : 현재 창에서 실행
_blank : 새 창에서 실행
ot : 이름을 붙여서 실행
→ 세번째 인자 : 그냥 모양에 관련된 (style)
<!DOCTYPE html><html><style>li {padding:10px; list-style: none}</style><body><ul><li>
첫번째 인자는 새 창에 로드할 문서의 URL이다. 인자를 생략하면 이름이 붙지 않은 새 창이 만들어진다.<br /><inputtype="button"onclick="open1()"value="window.open('demo2.html');" /></li><li>
두번째 인자는 새 창의 이름이다. _self는 스크립트가 실행되는 창을 의미한다.<br /><inputtype="button"onclick="open2()"value="window.open('demo2.html', '_self');" /></li><li>
_blank는 새 창을 의미한다. <br /><inputtype="button"onclick="open3()"value="window.open('demo2.html', '_blank');" /></li><li>
창에 이름을 붙일 수 있다. open을 재실행 했을 때 동일한 이름의 창이 있다면 그곳으로 문서가 로드된다.<br /><inputtype="button"onclick="open4()"value="window.open('demo2.html', 'ot');" /></li><li>
세번재 인자는 새 창의 모양과 관련된 속성이 온다.<br /><inputtype="button"onclick="open5()"value="window.open('demo2.html', '_blank', 'width=200, height=200, resizable=yes');" /></li></ul><script>functionopen1(){
window.open('demo2.html');
}
functionopen2(){
window.open('demo2.html', '_self');
}
functionopen3(){
window.open('demo2.html', '_blank');
}
functionopen4(){
window.open('demo2.html', 'ot');
}
functionopen5(){
window.open('demo2.html', '_blank', 'width=200, height=200, resizable=no');
}
</script></body></html>
웹사이트가 가지고 있는 기능이 우리의 브라우저를 제어할 수 있게 되면 그것이 바로 보안 취약점이다. 때문에 브라우저에서 어떤 스크립트를 실행되게 할 지 설정할 수 있다. 같은 도메인에 있는 서버와 사용자라면 자유자재로 값을 변경할 수 있지만 다른 도메인인 경우 원격하는 데에 제한이 생긴다 이것을 팝업 차단이라고 한다.
즉 window.open 은 팝업 차단에 걸릴 수 있다는 것을 기억하자.
5. DOM
웹 페이지를 자바스크립트로 제어하기 위한 객체 모델을 의미한다. window 객체의 document 프로퍼티를 통해서 사용할 수 있다. window 객체가 창을 의미한다면 document 객체는 윈도우에 로드된 문서를 의미한다고 할 수 있다.
5.1. 제어 대상 찾기
문서를 자바스크립트로 제어하려면 제어의 대상에 해당되는 객체를 찾는 것이 제일 먼저 할 일이다. 문서 내에서 객체를 찾는 방법은 document 객체의 메소드를 이용한다.
document.getElementsByTagName
document.getElementsByClassName
document.getElementById
document.querySelector
document.querySelectorAll
5.2. Jquery
현재 많은 사람들이 사용하는 자바스크립트 라이브러리 이다. 이것을 이용해서 훨씬 쉽게 원하는 태그나 DOM을 조회하고 검색할 수 있다. 즉, 웹페이지를 쉽게 조작할 수 있도록 돕는 도구이다. jquery를 사용하기 위해서는 jQuery를 HTML로 로드해야 한다. 아래는 jQuery를 로드하는 방법이다.
이를 통해서 알 수 있는 것은 엘리먼트의 종류에 따라서 리턴되는 객체가 조금씩 다르다는 것이다.
*DOM Tree
모든 엘리먼트는 HTMLElement의 자식이다. 따라서 HTMLElement의 프로퍼티를 똑같이 가지고 있다. 동시에 엘리먼트의 성격에 따라서 자신만의 프로퍼티를 가지고 있는데 이것은 엘리먼트의 성격에 따라서 달라진다. HTMLElement는 Element의 자식이고 Element는 Node의 자식이다. Node는 Object의 자식이다. 이러한 관계를 DOM tree 라고 한다.
이 관계를 그림으로 나타내면 아래와 같다.
이러한 관계를 이해하지 못하면 필요한 API를 찾아내는 것이 어렵거나 몹시 혼란스러울 것이다. 다행인 것은 jQuery와 같은 라이브러리를 이용한다면 이러한 관계를 몰라도 된다.
*HTMLCollection
HTMLCollection 은 리턴결과가 복수인 경우에 사용하게 되는 객체다. 유사배열로 배열과 비슷한 사용방법을 가지고 있지만 배열은 아니다.
<!DOCTYPE html><html><body><ul><li>HTML</li><li>CSS</li><liid="active">JavaScript</li></ul><script>console.group('before');
var lis = document.getElementsByTagName('li');
for(var i = 0; i < lis.length; i++){
console.log(lis[i]);
}
console.groupEnd();
console.group('after');
lis[1].parentNode.removeChild(lis[1]);
for(var i = 0; i < lis.length; i++){
console.log(lis[i]);
}
console.groupEnd();
</script></body></html>
이 복수형은 특이점이 있는데 바로 목록이 실시간으로 변경된다는 것이다. 즉, 태그를 추가하거나 변경하는 경우 이 유사배열 내의 값도 달라진다.
cf) console.group 은 그룹 별로 콘솔에 띄워주는 매소드이다. 예를 들어 group('before') 이라고 치면 해당 before 트리가 생긴다. 즉 위의 코드를 실행시키면 다음과 같이 된다
이 그룹을 끝내고 싶으면 console.groupEnd() 를 호출하면 된다.
5.4. Element 객체
element 객체는 엘리먼트를 추상화한 객체다. HTMLElement 객체와의 관계를 이해하기 위해서는 DOM의 취지에 대한 이해가 선행되야 한다.
DOM은 HTML만을 제어하기 위한 모델이 아니다. HTML이나 XML, SVG, XUL 과 같이 마크업 형태의 언어를 제어하기 위한 규격이기 때문에 Element는 마크업 언어의 일반적인 규격에 대한 속성을 정의하고 있고, 각각의 구체적인 언어를 위한 기능은 HTMLElement, SVGElement, XULElement와 같은 객체를 통해서 추가해서 사용하고 있다.
*다른 객체들과의 관계
DOM의 계층구조에서 Element 객체의 위치는 아래와 같다.
이 때 왜 굳이 Element 와 HTMLElement 를 나누었을까?
마크업 언어를 제어하기 위한 규격이 DOM 이라, 다른 말로 DOM 표준은 HTML, XML, SVG, XUL 등등의 마크업 들을 제어하기 위한 표준이라 할 수 있기 때문에 모든 Element 들의 기능들을 제어하기 위해 Element 객체를 따로 두었다.
예를 들어 style 이라는 프로퍼티는 Element에는 없고 HTMLElement 에 있는 프로퍼티이다. (다른 언어는 필요 없을 수 있기 때문에)
상세한 프로퍼티는 개발자 도구에 들어가서 확인할 수 있다. 밑으로 갈수록 상속 관계이니 직접 확인해보자.
*주요 기능
1) 식별자
문서 내에서 특정한 엘리먼트를 식별하기 위한 용도로 사용되는 API
엘리먼트를 제어하기 위해서는 그 엘리먼트를 조회하기 위한 식별자가 필요하다. HTML에서 엘리먼트의 이름과 id 그리고 class 는 식별자로 사용된다. 식별자 API는 이 식별자를 가져오고 변경하는 역할을 한다.
재귀적 호출에 대한 개념을 먼저 잡고 넘어가자. 그 이유는 완전 탐색 시에, 해당 호출 방식을 자주 활용하기 때문이다.
재귀함수의 기본적인 이해
재귀함수란: 함수 내에서 자기 자신을 다시 호출하는 함수
: 자신이 수행할 작업을 유사한 형태의 여러 조각으로 쪼갠 뒤 그 중 한 조각을 수행하고, 나머지를 자기 자신을 호출해 실행하는 함수
재귀함수 호출방식
voidRecursiveFunction(void){
printf("Recursive function example1 \n");
RecursiveFunction();
}
※ 기저 사례 (base case)
▷ 더 이상 쪼개지지 않는 가장 작은 작업, 즉 최소한의 작업에 도달했을 때 답을 곧장 반환하는 조건문에 포함될 내용 ▷ 기저 사례를 선택할 때는 존재하는 모든 입력이 항상 기저 사례의 답을 이용해 계산될 수 있도록 신경써야 한다.
# 완전탐색(exhaustive search)
① 완전탐색이란?
▷ '무식하게 푼다(brute-force)'는 컴퓨터의 빠른 계산 능력을 이용해 가능한 경우의 수를 일일이 나열하면서 답을 찾는 방법을 의미. 이렇게
가능한 방법을 전부 만들어 보는 알고리즘
을 뜻한다. ▷ 완전 탐색은 컴퓨터의 빠른 계산 속도를 잘 이용하는 방법이다. ▷ (예제) n개의 원소 중 m개를 고르는 모든 조합을 출력하는 코드
// n : 전체 원수의 수 // picked : 지금까지 고른 원소들의 번호 // toPick : 더 고를 원소의 수// 일 때, 앞으로 toPick개의 원소를 고르는 모든 방법을 출력한다. voidpick(int n, vector<int>& picked, int toPick) {
// 기저 사례 : 더 고를 원소가 없을 때 고른 원소들을 출력한다. if(toPick == 0) {
printPicked(picked);
return;
}
// 고를 수 있는 가장 작은 번호를 계산한다.
int smallest = picked.empty() ? 0 : picked.back() + 1;
// 이 단계에서 원소 하나를 고른다. for(int next = smallest; next < n; ++next) {
picked.push_back(next);
pick(n, picked, toPick - 1);
picked.pop_back();
}
}
② 완전 탐색 방법
Brute Force for문과 if문을 이용하여 처음부터 끝까지 탐색하는 방법
비트마스크: 거두절미 하고 이야기 하면, 비트마스크는 알고리즘 이라기 보단 테크닉에 가깝습니다. 비트는 컴퓨터에서 다루는 최소 단위이며, 정수를 이진수로 표현, 비트 연산을 통해 문제를 해결해 나가는 기술을 비트마스크 라고 한다.
순열 순열의 시간 복잡도는 O(N!)으로 백트래킹과 비슷하다. check 배열 하나 두고 들어갔다가 나오고, 들어갔다가 나오는 방식을 구현한다. 예시는 밑에 추가해놨으니 참고해보자.
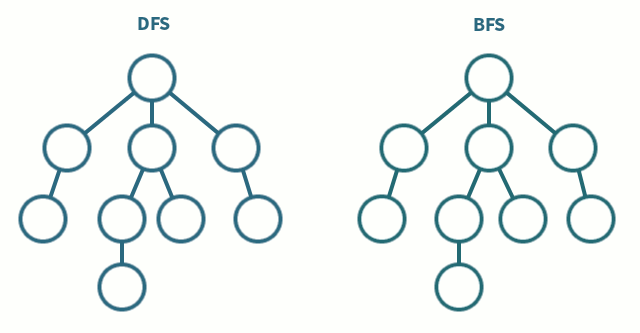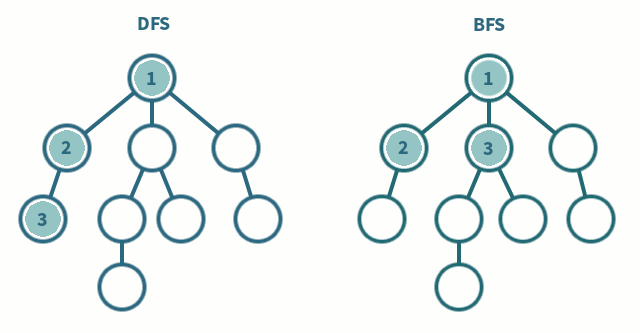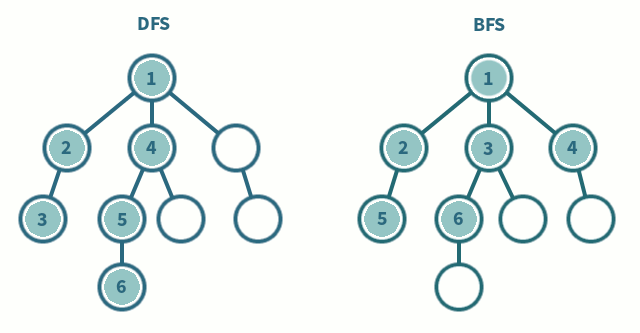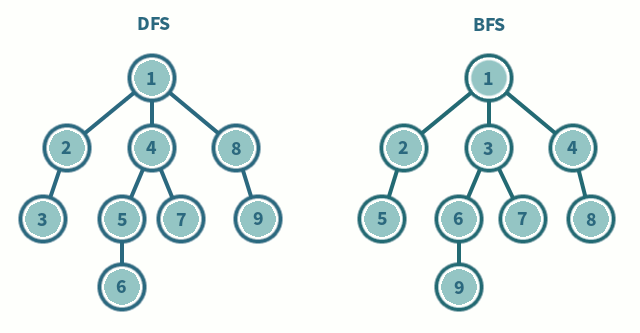
백트래킹(DFS): 백트래킹은 모든 조합의 수를 살펴보는 것인데 단 조건이 만족할 때 만이다. 모든 경우의 수를 모두 찾는 것보다 ‘경우에 따라' 훨씬 빠를 수 있다. 왜냐하면 조건이 만족하는 경우라는 조건이 있기 때문이다.한 컬럼에 Queen을 두었으면 오른쪽 컬럼에 가능한 자리에 Queen을 둔다. 또 다시 오른쪽 컬럼 중에서 가능한 자리에 Queen을 둔다. 이 과정을 반복한다. 만약에 N개의 Queen을 두었다면 카운트를 증가 시킨다. 이제부터가 중요한데, 성공하기 직전으로 상태를 되돌린다(back). 그리고 N번째 컬럼 중 다른 칸들을 시도한다. 만약에 없다면 N-1번째 컬럼에 있는 Queen을 들어서 다음으로 가능한 칸으로 옮긴다. 다시 N번째 컬럼에 Queen을 둘 수 있는 곳을 찾는다. N-1번째 컬럼의 모든 경우를 시도했다면, N-2번째로 되돌아가 다음으로 가능한 위치로 Queen을 옮긴다.
구체적인 예를 들어보자. 정렬되어 있지 않은 숫자 리스트 중에 특정 숫자를 찾는 것은 n을 리스트 길이라고 했을 때, O(n) 시간 복잡도를 갖는다. 이 경우에는 백트래킹은 의미가 없다. 한 개씩 모두 살펴볼 수 밖에 없기 때문이다. 반면 N-Queen 문제의 경우는 다르다.
#include<iostream>#include<vector>#define MAX 5 usingnamespace std;
char Arr[MAX];
bool Check[MAX];
vector<char> V;
voidPermutation(int n, int r){
if (n == r) {
for (int i = 0; i < V.size(); i++) {
cout << V[i] << " ";
}
cout << endl;
return;
}
for (int i = 0; i < MAX; i++){
if (Check[i] == true) continue;
Check[i] = true;
V.push_back(Arr[i]);
Permutation(n+1 , r);
V.pop_back();
Check[i] = false;
}
}
intmain(void){
Arr[0] = 'a';
Arr[1] = 'b';
Arr[2] = 'c';
Arr[3] = 'd';
Arr[4] = 'e';
Permutation(0,2);
}
#include<iostream>#include<vector>#define MAX 5 usingnamespace std;
char Arr[MAX];
bool Check[MAX];
vector<char> V;
voidcombination(int idx, int n, int r){
if (n == r){
for (int i = 0; i < MAX; i++){
if (Check[i] == true){
cout << Arr[i] << " ";
}
}
cout << endl;
return;
}
for (int i = idx; i < MAX; i++) {
if (Check[i] == true) continue;
Check[i] = true;
combination(i,n+1,r);
Check[i] = false;
}
}
intmain(void){
Arr[0] = 'a';
Arr[1] = 'b';
Arr[2] = 'c';
Arr[3] = 'd';
Arr[4] = 'e';
combination(0,0,2);
}
위의 5가지 방법을 이용한 완전탐색 방법 모두를 익히는 것이 좋다.
모든 경우의 수를 탐색하는 방법은 문제를 접했을 때 가장 쉬운 방법이지만, 기초라고도 볼 수 있다. 그리고 문제에서 제한조건과 위의 몇 가지 SKILL을 추가하여 푼다면 문제 해결 시간을 크게 향상 시킬 수 있다. 참고로 완전탐색을 완벽하게 하기 위해서는 DFS, BFS 등등 코드를 두루두루 알고 있어야 한다.